

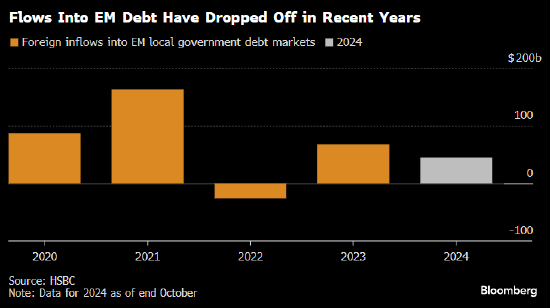
专题:英伟达营收同比增长94% 超预期但无法满足投资者的高期望
英伟达今日公布了该公司的2025财年第三财季财报。报告显示,英伟达第三财季营收为350.82亿美元,同比增长94%,环比增长17%;不按照美国通用会计准则的调整后净利润为200.10亿美元,同比增长100%,环比增长18%(注:英伟达财年与自然年不同步,2025年1月底至2025年1月底为2025财年)。
英伟达预计2025财年第四财季营收将达375亿美元左右,超出分析师平均预期,但与最高预期的410亿美元相比存在差距。
财报发布后,英伟达创始人、总裁兼首席执行官黄仁勋和执行副总裁兼首席财务官科莱特·克雷斯等高管出席随后召开的财报电话会议,解读财报要点并回答分析师提问。
以下是分析是问答环节主要内容:
Cantor Fitzgerald分析师C.J. Muse:在大型语言模型扩展规模方面,显然我们现在还处于非常早期的阶段,想知道公司是如何帮助客户处理模型扩展方面出现的问题的?当然,有些服务器集群尚未采用Blackwell架构,这是否会引发对该产品更大的需求?
黄仁勋:基础模型方面,预训练的扩展规模仍在进行且进展良好。这是我从观察中看到的,而非物理定律角度得出的判断,有证据表明它仍在不断扩展。然而我们认为仅仅这样是不够的,我们已经发现了另外两种扩展的方式。
一种是训练后扩展,当然,第一代训练后扩展是强化人类反馈,但现在我们有了强化学习人工智能反馈。而且所有形式的合成数据都已生成,这些数据有助于训练后扩展。其中,最重大、最令人振奋的进展之一就是ChatGPT o1(Strawberry)模型,它实现了推断时间扩展,也就是之前所讲的测试时间扩展。它思考的时间越长,给出的答案质量就越高,而且它会考虑使用像思维链、多路径规划以及各种各样思考所需的方法,有点像我们人类在回答问题之前先在头脑中进行思考的过程。所以我们现在已经有了三种扩展方式,也正因为如此,我们看到对公司基础设施的需求真的很大。
在上一代基础模型的末期,大概是十万个Hopper的规模,下一代则从十万个Blackwell开始,这样大家大概就能了解到这个行业在预训练扩展、训练后扩展,以及现在非常重要的推理时间扩展方面的发展趋势了,需求真的很大。
与此同时,对于我们公司来说,推理方面的扩展真的已经开始了,英伟达是当今世界上最大的推理平台,已安装的设备数量非常庞大,所有在Ampere架构和Hopper架构上训练的内容,其推理也令人难以置信地在Ampere架构和Hopper架构上进行。随着我们将Blackwell用于训练基础模型,未来同样会为推理留下了庞大的设备基数。
所以,我们看到推理需求在上升,推理时间扩展在上升,原生人工智能公司的数量在持续增长,当然,我们也开始看到企业对代理式人工智能(Agentic AI)的采用,这确实是当下最新的潮流,我们看到来自很多不同地方的大量需求。
高盛分析师Toshiya Hari:黄仁勋在今年早些时候进行了大规模变革,然后上周末有一些报道提到公司芯片产品出现的散热问题。另外,已经有投资者询问你如何执行今年在游戏开发者大会(GDC)上所展示的路线图,包括明年上市的Ultra芯片和2026年向Rubin平台的过渡等。能否请你讲讲这方面的情况?一些投资者对于公司能否按时执行计划存在疑问。另外一个问题关于供应短缺,我想知道是多种零部件导致了这种情况,还是具体是因为某种特定芯片或组件,比如CoWoS封装或者HBM芯片方面的问题?短缺的情况是在好转还是在恶化?
黄仁勋:关于最后一个问题,Blackwell的生产正在全力推进,正如科莱特之前提到的,我们本季度的交付量将会超过之前的预估。供应链团队在与供应伙伴合作以增加Blackwell的产量方面做得非常出色,而且我们会在明年继续努力提高其产量。目前的情况是市场需求超过了我们的供应,我们正身处在这场生成式人工智能变革初期,所以这是预料之中的。新一代能够进行推理、能够长时间思考的基础模型刚刚推出,其中一个非常令人振奋的领域便是实体人工智能,即能够理解真实世界结构的人工智能,所以Blackwell的需求非常强劲,我们的执行情况也很顺利,团队在全球范围内正在开展大量的工程工作。包括大家看到的戴尔和CoreWeave正在搭建相关系统,甲骨文公司搭建的系统,微软也有相关系统,即将采用Grace Blackwell系统,谷歌(Google)也有相关系统,所有这些云服务提供商都在争抢先机。
英伟达和这些公司一道开展相当复杂的工程工作,原因在于虽然我们构建了全栈和完整的基础设施,但我们需将这些人工智能超级计算机进行拆分,并集成到世界各地的定制数据中心和架构中。这个集成过程我们已经经历了好几代,现在已经很擅长了,但仍然有大量的工程工作要做,从所有正在搭建的系统来看,Blackwell的情况非常好,而且正如我们之前提到的,本季度我们计划发货的数量超过了之前的预估。
关于供应链,我们建造了七种不同的定制配置,以便交付Blackwell系统,这些系统可以采用风冷或液冷方式,有NVLink 8或NVLink 72,或者NVLink 8、NVLink 36、NVLink 72等不同组合,还有X86或Grace架构,将所有这些系统集成到世界各地的数据中心上,简直可以说就是一个奇迹。
要实现这样规模的产能提升,对应的所需零部件的供应链情况,你得回头看看我们上季度的Blackwell发货量是零,而本季度Blackwell系统的总发货量是以十亿为单位来衡量的,产能提升的速度令人难以置信,似乎世界上几乎每家公司都参与到了英伟达的供应链中,我们有很棒的合作伙伴,从台积电到安费诺(Amphenol)、Vertiv、SK海力士、美光、Spil、安普科(Ampcore)、京瓷(Kyec),还有富士康(FOXconn)及其建造的众多工厂、广达(Quanta)、纬颖(Wiwynn)、戴尔、惠普(HP)、超微(Supermicro)、联想(Lenovo)等等。参与Blackwell产能提升的公司数量真的相当惊人,我非常感激这些合作伙伴。
最后,关于我们执行路线图的问题,公司有年度路线图,并且预计会继续按照年度路线图执行,这样做,我们当然能够提高平台的性能。同样非常重要的是,当我们以数倍的幅度提高性能时,我们就在降低训练成本、降低推理成本、降低人工智能的成本,使其能够更容易被大众所使用。另一个需要注意的重要因素是,一个固定规模的数据中心——数据中心总是有一定的固定规模,过去可能是几十兆瓦,现在大多数数据中心是一百兆瓦到几百兆瓦,我们还在规划千兆瓦级的数据中心——不管数据中心规模多大,电力都是有限的,而当你处于电力有限的数据中心时,每瓦特的最高性能会直接转化为我们合作伙伴的最高收益。
所以一方面,我们的年度路线图降低了成本,另一方面,因为我们每瓦特电力所创造的性能比其他任何产品都要好,我们为客户创造了尽可能高的收益,所以这个年度节奏对我们来说非常重要,据我所知,一切都在按计划进行。
(持续更新中。。。)









发表评论